Funktionsweise von ChatGPt
📝 Auftrag 1: Einführungsvideo
Schau dir als Einstieg dieses Video zu den Grundlagen der künstlichen Intelligenz an.

So funktioniert ChatGPT & Co (6:04)
Was ist ein Large Language Model (LLM)?
Ein Large Language Model (LLM) ist im Grunde ein sehr fortgeschrittenes Computer-Programm, das gelernt hat, menschliche Sprache zu verstehen und zu verwenden. Stell dir vor, du würdest das gesamte Internet lesen – Milliarden von Büchern, Artikel, Gesprächen und Texten – und dabei Muster erkennen, wie Menschen Sätze bilden, Fragen beantworten und Ideen ausdrücken. Genau das macht ein LLM, nur viel schneller. Während des Trainings analysiert es riesige Textmengen und lernt, welche Wörter normalerweise zusammen vorkommen, wie Grammatik funktioniert und wie man auf verschiedene Fragen oder Aufgaben reagiert. Das Ergebnis ist ein System, das Texte schreiben, Fragen beantworten, beim Programmieren helfen oder sogar kreative Geschichten erfinden kann.
Wichtig zu wissen ist, dass ein LLM nicht wirklich "denkt" wie ein Mensch – es hat keine eigenen Gefühle oder Bewusstsein. Es ist eher wie ein extrem guter Algorithmus, welcher Muster erkennt und auf der Basis seiner Trainingsdaten die Wahrscheinlichkeit vorhersagt, welche Antwort am besten zu deiner Frage passt. Ein LLM basiert auf der Verarbeitung von Tokens und der Berechnung von Wahrscheinlichkeitsverteilungen
Was sind Tokens?
Tokens sind die kleinen Häppchen, in die ein LLM Text zerlegt. Ein Token kann ein ganzes Wort sein (wie "Hund"), ein Wortteil (wie "un-glaub-lich") oder sogar nur ein einzelnes Zeichen. Das LLM verarbeitet Text immer als diese Token-Stücke – ungefähr 100 Tokens entsprechen etwa 75 Wörtern. Tokens sind sozusagen die "Sprache", die das Modell intern versteht.
📝 Auftrag 2: Tokenizer
Probiere dieses interaktive Online-Tool aus, welches visualisiert, wie OpenAIs Tokenizer funktioniert. Es zeigt dir, wie das Sprachmodell deine Texteingabe in Tokens zerlegt. Theoretisch könnte jedes Wort oder jedes Zeichen ein Token sein.
Beispiel: «Wie heisst die Hauptstadt von Frankreich?»
- 6 Wörter
- 8 Tokens
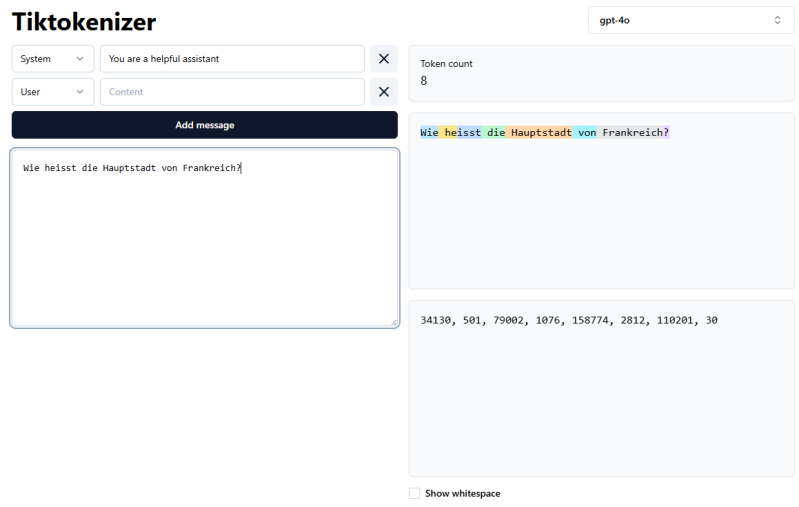
Token-IDs
Die Zahlen (34130, 501, 79002, ...) im unteren Fenster sind die Token-IDs - also die "Geheimsprache", die das Modell intern verwendet.
Stell dir das so vor:
Das Sprachmodell hat ein riesiges Wörterbuch mit etwa 100.000 Einträgen. Jeder Eintrag (jedes Token) hat eine feste Nummer, wie in einem Katalog:
- Eintrag Nr. 34130 = "Wie"
- Eintrag Nr. 501 = " heisst"
- Eintrag Nr. 79002 = " die"
- Eintrag Nr. 1076 = " Haupt"
- Eintrag Nr. 158774 = "stadt"
- Eintrag Nr. 2812 = " von"
- Eintrag Nr. 110201 = " Frank"
- Eintrag Nr. 30 = "reich?"
Warum braucht das Modell diese Zahlen?
Computer können nicht direkt mit Wörtern rechnen - sie brauchen Zahlen! Also wird jedes Token in seine ID-Nummer umgewandelt. Das Modell rechnet dann mit diesen Zahlen (durch neuronale Netze), um die Bedeutung zu verstehen und die nächsten Tokens vorherzusagen.
Kurz gesagt: Der Text wird erst in Tokens zerlegt (die bunten Wörter), und diese Tokens werden dann in Zahlen übersetzt (die IDs), damit der Computer damit arbeiten kann.
Wie schreiben Sprachmodelle Text?
Beispiel: Du fragst "Was ist die Hauptstadt von Frankreich?"
-
Tokenisierung: Deine Frage wird in Tokens zerlegt: ["Was", "ist", "die", "Haupt", "stadt", "von", "Frank", "reich", "?"]
-
Verarbeitung: Das Modell analysiert diese Tokens und versteht den Kontext der Frage
-
Vorhersage des ersten Tokens: Das Modell berechnet Wahrscheinlichkeiten für das nächste Token. Beispiel: "Die" (85%), "Paris" (10%), "Frankreichs" (3%)...
-
Auswahl (Sampling): Das Token wird sampled (ausgewählt) basierend auf den Wahrscheinlichkeiten. Die Temperature steuert dabei, wie kreativ oder vorhersehbar die Auswahl ist (niedrige Temperature = sicherer, hohe Temperature = zufälliger)
-
Wiederholung: Jetzt wird das nächste Token vorhergesagt basierend auf "Was ist die Hauptstadt von Frankreich? Die" → wahrscheinlichstes Token: "Hauptstadt"
-
Iteration: Dieser Prozess wiederholt sich Token für Token → "ist" → "Paris" → "."
-
Stopp (End of Sequence): Das Modell erzeugt ein spezielles End of Sequence-Token oder erkennt, dass die Antwort vollständig ist und stoppt die Generierung
Ergebnis: "Die Hauptstadt ist Paris."
Jedes Token wird also einzeln erzeugt, basierend auf allen vorherigen Tokens!
SoekiaGPT
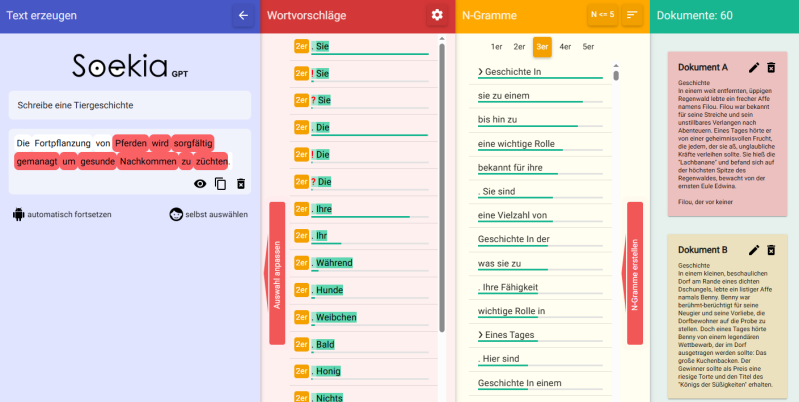
Link zu Online-Tool: https://www.soekia.ch/gpt.html
SoekiaGPT ist ein spezielles Lernprogramm für den Unterricht, mit dem du hinter die Kulissen von Textgeneratoren wie ChatGPT schauen kannst. Es wurde extra für Schulen entwickelt (aus der Schweiz) und ist kostenlos nutzbar.
Was macht SoekiaGPT besonders?
Im Gegensatz zu echten KI-Sprachmodellen wie ChatGPT ist SoekiaGPT bewusst stark vereinfacht. Es zeigt dir visuell und Schritt für Schritt:
- Wie Textgenerierung funktioniert: Du siehst live, welche Wortvorschläge das Modell hat und warum es sich für ein bestimmtes Wort entscheidet
- Die Textgrundlage: Du kannst sehen, aus welchen Dokumenten das Modell "lernt" (z.B. Märchen oder Wetterberichte)
- N-Gramme: Das sind Wortfolgen, die das Modell analysiert (z.B. "Es war einmal")
- Wahrscheinlichkeiten: Welches Wort kommt statistisch am häufigsten als nächstes?
Was kannst du damit lernen?
Du erkennst, welchen riesigen Einfluss die Textgrundlagen auf die Qualität der erzeugten Texte haben. Zum Beispiel: Wenn du dem Modell nur falsche Texte gibst ("Die Erde ist eine Scheibe"), wird es auch falsche Antworten generieren!
Der große Unterschied zu ChatGPT:
SoekiaGPT nutzt nur einfache Statistik statt komplexer neuronaler Netze - deshalb sind die Texte oft holprig oder lustig. Aber genau das macht es perfekt zum Lernen, weil du jeden einzelnen Schritt nachvollziehen kannst!
📝 Auftrag 3: Textgenerator testen
Öffne das Online-Tool SoekiaGPT und wähle die Zielsprache Deutsch aus. Starte nun SoekiaGPT mit dem blauen Knopf unten.
Versuche unterschiedliche Einstellungen im Programm und erfahre die direkten Auswirkungen auf den Text. Hier einige Vorschläge:
Vorschlag 1:
Lass dir autmatisch eine Tiergeschichte schreiben. Du kannst die Texterstellung mit der Pausentaste stoppen. Ebenfalls kannst du die Geschichte mit dem Symbol "Abfalleimer" löschen und neu starten.

Vorschlag 2:
Lade eine neue Quelle/Kollektion. Betätige dazu oben rechts den Knopf "Schau hinein". Klicke auf das mittlere Symbol in der waagrechten grünen Leiste. Es erscheinen 7 vorgefertigte Quellen:
- Märchen
- Fairy Tales
- Wetter
- Tiergeschichten
- Musik
- Tic Tac Toe
- Schachspiel
Wähle z. B. Märchen aus. Lass dir eine Märchen formulieren.

Vorschlag 3:
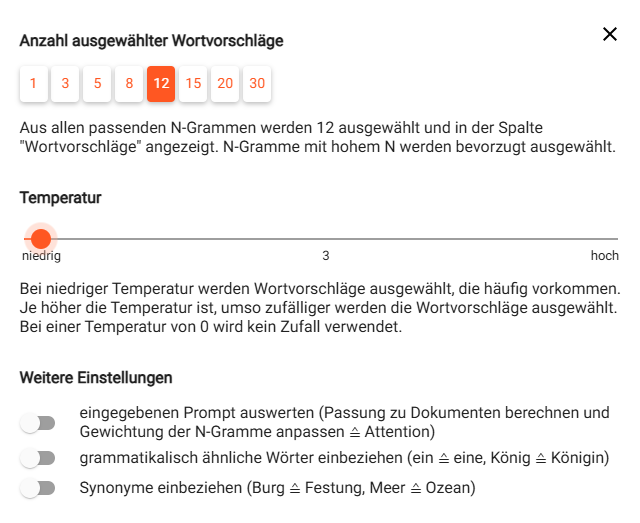
Verändere den Kontextbezug, indem du die Variable N im orangen Balken anpasst.
Je höher das N, desto längere Wortfolgen, desto mehr Kontext und desto eher grammatikalisch richtig.
Wenn du N <=2 machst, werden die Textvorschläge viel kürzer (nur 2 Tokens) und die Auswahl/Anzahl wird viel kleiner.

Vorschlag 4:
Produziere gewagt Text mit zufälligen Wortvorschlägen. Schiebe den Regler dazu über 70.
Vorschlag 5:
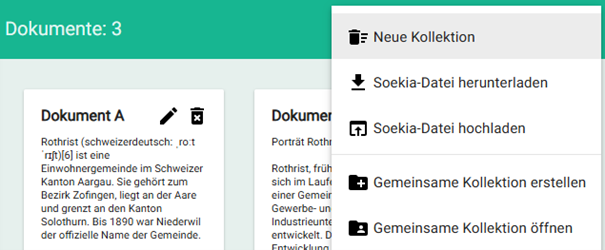
Erstelle eine eigene Kollektion von Texten über deinen Schulort. Füge mindestens 3 Textquellen in die Kollektion.
- Wikipedia
- Gemeindeseite
- Lokalzeitung
- ...
Lass das Programm nun ein Gemeindeportrait von Luzern schreiben.
Wichtige Erkenntnisse
- KI lernt aus den Trainingsdaten - auch Müll! Wenn die Quelle schlecht ist, ist auch die Ausgabe schlecht. "Garbage in, garbage out". Die Qualität und die Menge der Trainingsdaten sind entscheidend.
- KI reproduziert Vorurteile und Stereotype aus denTrainingsdaten - KI hat kein eigenes "Verständnis" von Gerechtigkeit oder Gleichberechtigung.
- Je mehr Kontext ein Modell hat, desto besser die Vorhersage. Das zeigt, warum moderne LLMs so riesige "Gedächtnisse" brauchen.
- Mit wenig Daten wiederholt sich das Modell ständig - das zeigt, warum ChatGPT Milliarden von Texten braucht.
- Das Modell produziert auch totalen Unsinn mit grosser Überzeugung - es zeigt, dass KI kein echtes "Verständnis" hat, sondern nur Muster mischt.
- Höhere Temperature/"Kreativität" bedeutet mehr Zufall - manchmal interessant, manchmal totaler Blödsinn.
- Das Modell kann nur "wissen", was in seinen Trainingsdaten steht - es erfindet aber trotzdem Antworten (Halluzination!)
Erstelle deine eigene Website mit Webador